
这篇博客记录的是在米盒项目的推荐需求中使用到的推荐算法
基于用户的协同过滤
* UserBasedCF的核心思想主要是找到和目标用户兴趣相似的用户集合,然后给目标用户推荐这个集合的用户喜欢的物品。关键在于计算用户与用户之间的兴趣相似度。这里主要使用余弦相似度来计算(wuv 代表用户 u 与 v 之间的兴趣相似度,N(u)表示用户 u 曾经喜欢过的物品集合, N(v) 表示用户 v 曾经喜欢过的物品集合):
* 根据上述核心思想,可以有如下算法步骤:
1. 建立用户-物品评分表及物品-用户倒排表
这里涉及到的物品有四种,包括文章,资料,文集,资料集,目前只实现文章和资料的推荐。由于是分别推荐,即文章和资料分开,用户对文章和资料的兴趣表现不同,因此计算相似度以及给用户推荐的时候都分开计算。首先是分别建立用户-文章评分表和用户-资料评分表。
//用户文章评分表 userid-articleid-score
Map<Integer,Map<Integer,Integer>> userItems = new HashMap<Integer, Map<Integer, Integer>>();
//用户-资料评分表 userid-resourceid-score
Map<Integer,Map<Integer,Integer>> userItems = new HashMap<Integer, Map<Integer, Integer>>();
用户-文章评分表依据的数据库表有articleset_user_relation, article_user_relation, 用户-资料评分表依据的数据库表有resourceset_user_relation, user_resource_relation, 现在开始从数据库表中读取数据并构造用户文章评分表及用户资料评分表,为节省时间,在构造评分表的同时
2. 建立物品-用户的倒排表
3. 用户与用户之间的共现矩阵 C[u][v],表示用户u与v喜欢相同物品的个数
4. 用户与用户之间的相似度矩阵 W[u][v],根据上述相似度计算公式计算。
5. 用上面的相似度矩阵来给用户推荐和他兴趣相似的用户喜欢的物品。用户 u 对物品 i 的兴趣程度可以估计为 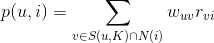
基于物品的协同过滤
参考资料: